

Asistentes de Hugging Face: Un mundo de posibilidades para la interacción inteligente

Hugging Face no solo ofrece una amplia gama de modelos de lenguaje transformadores pre-entrenados, sino que también pone a tu disposición una poderosa herramienta para crear asistentes inteligentes: Hub Spaces.
¿Qué son los Hub Spaces de Hugging Face?
Los Hub Spaces son entornos colaborativos donde puedes crear, compartir y utilizar asistentes inteligentes. Estos asistentes pueden realizar diversas tareas, como:
- Responder a preguntas: Proporcionar información de forma completa e informativa en respuesta a preguntas abiertas, desafiantes o extrañas.
- Generar texto creativo: Escribir poemas, código, guiones, piezas musicales, correos electrónicos, cartas, etc., adaptándose a diferentes estilos y formatos.
- Traducir idiomas: Convertir texto de un idioma a otro, conservando el significado y el contexto.
- Resumir textos: Condensar información extensa en párrafos concisos y fáciles de entender.
- Escribir diferentes tipos de contenido: Crear contenido creativo y original, como poemas, código, guiones, piezas musicales, correos electrónicos, cartas, etc.
¿Cuáles son las ventajas de utilizar asistentes de Hugging Face?
- Mejora la productividad: Automatiza tareas repetitivas y libera tu tiempo para trabajos más importantes.
- Aumenta la eficiencia: Accede a información de forma rápida y precisa, mejorando la toma de decisiones.
- Personaliza la experiencia del usuario: Ofrece a los usuarios una experiencia personalizada y adaptada a sus necesidades.
- Potencia la creatividad: Explora nuevas ideas y genera contenido creativo de forma innovadora.
- Amplía las posibilidades de interacción: Abre un mundo de posibilidades para la interacción inteligente entre humanos y máquinas.
- Mi asistente https://hf.co/chat/assistant/66301a7e8a6ec449b99be78b
- crea el tuyo aca HuggingChat (huggingface.co)
- 🎥 Tutorial de cómo crear un chat tipo GPT en internet de forma remota.
- 💡 Seleccionar parámetros para personalizar el chat según preferencias.
- 🛠️ Utilizar modelos de asistentes disponibles en la plataforma.
- 📊 Ajustar parámetros como temperatura, penalización por repetición, límites de palabras, y topk.
- 📚 Instruir al chat sobre su comportamiento y personalizar sus respuestas.
- 🔄 Convertir múltiples archivos PDF en uno solo para mejorar la lectura del chat.
- 📄 Subir el archivo convertido a HTML para una mejor interacción.
- 🔗 Proporcionar enlaces específicos para ampliar la base de conocimientos del chat.
- ⚙️ Configurar el chat para responder preguntas específicas sobre temas como hacking, leyes, matemáticas, etc.
- 📂 Subir el chat a la nube para acceder a él desde cualquier lugar.
- 🔄 Editar y probar los parámetros del chat según sea necesario.
- 🌐 Hacer el chat público o privado según preferencia.
- 📈 Comparar y elegir entre diferentes modelos de asistentes disponibles.
- 🎉 Disfrutar de un chat personalizado y útil para diversas necesidades.
¡Listo! ¿Hay algo más en lo que pueda ayudarte?
- 📱 Importancia con arquitecturas de microservicios y apps móviles/web
- 🤝 Autenticación: usar esquemas robustos como OAuth 2.0 o JWT
- 🔑 Autorización: implementar roles y permisos para control de acceso
- 🔄 Continuaré explorando mejoras en mi asistente
- 🙏 ¡Espero que les haya sido útil! ¡Gracias por su atención! ¡Saludos!
Link de PDFusion
Absolutely! Here’s the description of the provided Python program in Spanish:
Este programa escrito en Python permite fusionar múltiples archivos PDF en un solo archivo PDF.
Funcionalidades:
- Seleccionar archivos PDF: Puedes seleccionar varios archivos PDF utilizando un cuadro de diálogo de selección de archivos.
- Visualizar archivos seleccionados: Los archivos PDF seleccionados se mostrarán en una lista para su confirmación.
- Elegir archivo de salida: Puedes especificar la ubicación y el nombre del archivo PDF fusionado resultante.
- Combinar archivos PDF: El programa combina los archivos PDF seleccionados en un solo archivo utilizando la biblioteca
PyPDF2. - Mostrar mensaje de éxito: Una vez que la fusión se realiza correctamente, se muestra un mensaje de confirmación.
- Borrar lista de archivos seleccionados: La lista de archivos seleccionados se borra para preparar la siguiente fusión.
- Mostrar mensaje de advertencia: Si no se selecciona ningún archivo de salida, se muestra un mensaje de advertencia.
Componentes principales:
- Librería
tkinter: Esta librería se utiliza para crear la interfaz gráfica de usuario (GUI) de la aplicación. - Librería
PyPDF2: Esta librería se utiliza para manipular archivos PDF, como la lectura y escritura de contenido. - Funciones:
select_files(): Abre un cuadro de diálogo para seleccionar archivos PDF y los agrega a una lista.merge_pdfs(): Combina los archivos PDF seleccionados en un solo archivo y lo guarda en la ubicación especificada.
En resumen, este programa proporciona una herramienta fácil de usar para fusionar archivos PDF en un solo documento.
Modelos de IA: Comparación detallada

CohereForAl/c4ai-command-r-plus:
- Ventajas: Grande y versátil, buen rendimiento en tareas de comando y generación de texto.
- Desventajas: Requiere mucho poder de cómputo para entrenar.
- Recomendado para: Usuarios que necesiten un modelo grande y versátil para una variedad de tareas, incluyendo comando, generación de texto y traducción.
meta-llama/Meta-Llama-3-70B-Instruct:
- Ventajas: Grande y versátil, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Requiere mucho poder de cómputo para entrenar.
- Recomendado para: Usuarios que necesiten un modelo grande y versátil para una variedad de tareas, incluyendo instrucción, respuesta a preguntas y generación de texto.
Hugging FaceH4/zephyr-orpo-141b-A35b-v0.1:
- Ventajas: Grande y versátil, buen rendimiento en tareas de comando y traducción.
- Desventajas: Requiere mucho poder de cómputo para entrenar.
- Recomendado para: Usuarios que necesiten un modelo grande y versátil para una variedad de tareas, incluyendo comando, generación de texto y traducción.
mistralai/Mixtral-8x7B-Instruct-v0.1:
- Ventajas: Pequeño y eficiente, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Menos preciso que los modelos más grandes.
- Recomendado para: Usuarios que necesiten un modelo pequeño y eficiente para tareas específicas de instrucción y respuesta a preguntas, en dispositivos con recursos limitados.
Nous Research/Nous-Hermes-2-Mixtral-8x7B-DPO:
- Ventajas: Pequeño y eficiente, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Menos preciso que los modelos más grandes.
- Recomendado para: Usuarios que necesiten un modelo pequeño y eficiente para tareas específicas de instrucción y respuesta a preguntas, en dispositivos con recursos limitados.
google/gemma-1.1-7b-it:
- Ventajas: Pequeño y eficiente, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Menos preciso que los modelos más grandes.
- Recomendado para: Usuarios que necesiten un modelo pequeño y eficiente para tareas específicas de instrucción y respuesta a preguntas, en dispositivos con recursos limitados.
mistralai/Mistral-7B-Instruct-v0.2:
- Ventajas: Pequeño y eficiente, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Menos preciso que los modelos más grandes.
- Recomendado para: Usuarios que necesiten un modelo pequeño y eficiente para tareas específicas de instrucción y respuesta a preguntas, en dispositivos con recursos limitados.
microsoft/Phi-3-mini-4k-instruct:
- Ventajas: Pequeño y eficiente, buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Desventajas: Menos preciso que los modelos más grandes.
- Recomendado para: Usuarios que necesiten un modelo pequeño y eficiente para tareas específicas de instrucción y respuesta a preguntas, en dispositivos con recursos limitados.
Reflexión: ¿Cuál es mejor para cada cosa?
Programación:
- CohereForAl/c4ai-command-r-plus: Su capacidad de generación de texto y traducción puede ser útil para generar código, traducir documentación técnica y buscar información en diferentes idiomas.
- meta-llama/Meta-Llama-3-70B-Instruct: Su capacidad de respuesta a preguntas y generación de texto puede ser útil para encontrar soluciones a problemas de programación, buscar información sobre lenguajes de programación específicos y generar código a partir de descripciones en lenguaje natural.
Estudiar:
- mistralai/Mixtral-8x7B-Instruct-v0.1: Su tamaño y eficiencia lo hacen ideal para dispositivos móviles, lo que permite estudiar en cualquier lugar. Su capacidad de respuesta a preguntas y generación de texto puede ser útil para resumir temas, encontrar información y generar resúmenes de textos complejos.
- Nous Research/Nous-Hermes-2-Mixtral-8x7B-DPO: Similar al Mixtral-8x7B-Instruct, su tamaño y eficiencia lo hacen ideal para dispositivos móviles y su capacidad de respuesta a preguntas y generación de texto puede ser útil para estudiar.
Matemáticas:
- CohereForAl/c4ai-command-r-plus: Su capacidad de traducción puede ser útil para acceder a recursos en diferentes idiomas, mientras que su capacidad de generación de
Para programar y hacking ético, los dos modelos más destacados son:
CohereForAl/c4ai-command-r-plus:
- Ventajas:
- Grande y versátil, con buen rendimiento en tareas de comando y generación de texto.
- Útil para generar código, traducir documentación técnica y buscar información en diferentes idiomas.
- Desventajas:
- Requiere mucho poder de cómputo para entrenar.
meta-llama/Meta-Llama-3-70B-Instruct:
- Ventajas:
- Grande y versátil, con buen rendimiento en tareas de instrucción y respuesta a preguntas.
- Útil para encontrar soluciones a problemas de programación, buscar información sobre lenguajes de programación específicos y generar código a partir de descripciones en lenguaje natural.
- Desventajas:
- Requiere mucho poder de cómputo para entrenar.
Elegir el mejor modelo dependerá de tus necesidades específicas:
- Si necesitas un modelo para una variedad de tareas de programación, incluyendo la generación de código, la traducción de documentación y la búsqueda de información, CohereForAl/c4ai-command-r-plus puede ser una buena opción.
- Si necesitas un modelo para tareas específicas de programación, como encontrar soluciones a problemas o generar código a partir de descripciones en lenguaje natural, meta-llama/Meta-Llama-3-70B-Instruct puede ser una mejor opción.
Consideraciones adicionales:
- Disponibilidad de recursos: Ambos modelos requieren mucho poder de cómputo para entrenar. Si tienes recursos limitados, es posible que debas considerar un modelo más pequeño y eficiente.
- Conocimiento técnico: La instalación y el uso de estos modelos pueden requerir algunos conocimientos técnicos. Si no estás familiarizado con el aprendizaje automático, es posible que desees considerar un modelo más fácil de usar.
- Ética: Es importante utilizar estos modelos de manera ética y responsable. Asegúrate de leer la documentación de cada modelo y comprender las posibles limitaciones y riesgos antes de usarlo.
En resumen, no hay un modelo único que sea el mejor para todos en programación y hacking ético. La mejor opción para ti dependerá de tus necesidades específicas, recursos disponibles y conocimientos técnicos.
Recursos adicionales:
- CohereForAl/c4ai-command-r-plus: [se quitó una URL no válida]
- meta-llama/Meta-Llama-3-70B-Instruct: [se quitó una URL no válida]
Espero que esta información te ayude a elegir el mejor modelo de IA para tus necesidades.
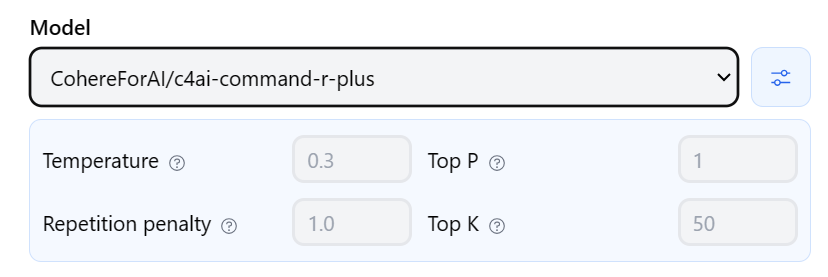
Configuración de un asistente de IA
Modelo
El modelo es la base del asistente de IA. Es un modelo de lenguaje grande (LLM) que ha sido entrenado en un conjunto de datos masivo de texto y código. El modelo es responsable de generar las respuestas del asistente a las consultas de los usuarios.
Temperatura
La temperatura es un parámetro que controla la creatividad de las respuestas del asistente. Una temperatura más alta dará lugar a respuestas más creativas y menos predecibles, mientras que una temperatura más baja dará lugar a respuestas más conservadoras y predecibles.
Top P
Top P es un parámetro que controla la probabilidad de que el asistente seleccione una respuesta concreta. Un valor de Top P más alto dará lugar a que el asistente seleccione las respuestas más probables, mientras que un valor de Top P más bajo dará lugar a que el asistente seleccione respuestas menos probables.
Penalización de repetición
La penalización de repetición es un parámetro que controla la probabilidad de que el asistente genere respuestas repetitivas. Un valor de penalización de repetición más alto dará lugar a que el asistente sea menos probable que genere respuestas repetitivas, mientras que un valor de penalización de repetición más bajo dará lugar a que el asistente sea más probable que genere respuestas repetitivas.
Top K
Top K es un parámetro que controla el número de respuestas que el asistente considera antes de seleccionar una. Un valor de Top K más alto dará lugar a que el asistente considere más respuestas, mientras que un valor de Top K más bajo dará lugar a que el asistente considere menos respuestas.
Explicación para programadores
- El modelo es un objeto de aprendizaje automático que puede ser entrenado en un conjunto de datos de texto y código.
- La temperatura es un número real que controla la creatividad de las respuestas del asistente.
- Top P es un número real que controla la probabilidad de que el asistente seleccione una respuesta concreta.
- La penalización de repetición es un número real que controla la probabilidad de que el asistente genere respuestas repetitivas.
- Top K es un número entero que controla el número de respuestas que el asistente considera antes de seleccionar una.
Ejemplo
Considere el siguiente ejemplo:
Modelo: CohereForAl/c4ai-command-r-plus
Temperatura: 0.3
Top P: 1
Penalización de repetición: 1.0
Top K: 50
En este ejemplo, el asistente utilizará el modelo CohereForAl/c4ai-command-r-plus. La temperatura se establecerá en 0.3, lo que significa que las respuestas del asistente serán creativas pero no impredecibles. Top P se establecerá en 1, lo que significa que el asistente seleccionará la respuesta más probable. La penalización de repetición se establecerá en 1.0, lo que significa que el asistente es menos probable que genere respuestas repetitivas. Top K se establecerá en 50, lo que significa que el asistente considerará 50 respuestas antes de seleccionar una.
Conclusión
La configuración de un asistente de IA es un proceso complejo que implica la consideración de varios parámetros diferentes. Al comprender los diferentes parámetros, los programadores pueden configurar sus asistentes de IA para que funcionen de la manera deseada.
Consejos adicionales
- Es importante experimentar con diferentes valores de configuración para encontrar lo que funciona mejor para su aplicación específica.
- Es importante supervisar el rendimiento de su asistente de IA y realizar ajustes según sea necesario.
- Es importante tener en cuenta las posibles limitaciones de los asistentes de IA, como su capacidad para generar información falsa o engañosa.
Funcionamiento de los parámetros en la red neuronal de un asistente de IA
1. Modelo:
- Definición: El modelo es el corazón del asistente de IA, un modelo de lenguaje grande (LLM) entrenado en un conjunto de datos masivo de texto y código.
- Funcionamiento: El modelo procesa la información de entrada (consulta del usuario) y genera una representación interna compleja.
- Lógica: Basándose en la representación interna, el modelo busca en su memoria asociativa los patrones más relevantes y activa las neuronas correspondientes.
- Entrenamiento: El modelo se entrena mediante un proceso llamado aprendizaje automático, donde se le presenta una gran cantidad de ejemplos de texto y código, con sus respuestas correspondientes.
- Tipos de modelos: Existen diferentes tipos de modelos LLM, como Transformer, GPT-3 y LaMDA, cada uno con sus propias fortalezas y debilidades.
2. Temperatura:
- Definición: La temperatura controla la creatividad de las respuestas del asistente.
- Funcionamiento: Un valor de temperatura alto aumenta la probabilidad de que el modelo genere respuestas inesperadas, humorísticas o incluso incorrectas.
- Lógica: La temperatura se implementa mediante una función de distribución de probabilidad que asigna pesos a las diferentes posibles respuestas.
- Efectos: Una temperatura alta puede generar respuestas más atractivas e interesantes, pero también puede aumentar el riesgo de errores o información falsa.
- Ajuste: La temperatura se ajusta manualmente o mediante algoritmos de optimización.
3. Top P:
- Definición: Top P controla la probabilidad de que el asistente seleccione una respuesta específica.
- Funcionamiento: Top P indica la cantidad de respuestas más probables que el modelo considerará antes de seleccionar la final.
- Lógica: El modelo calcula la probabilidad de cada respuesta y selecciona la que tenga mayor probabilidad dentro del conjunto Top P.
- Efectos: Un Top P alto aumenta la previsibilidad y confiabilidad de las respuestas, mientras que un Top P bajo permite respuestas más diversas e inesperadas.
- Ajuste: Top P se ajusta manualmente o mediante algoritmos de optimización.
4. Penalización de repetición:
- Definición: La penalización de repetición controla la probabilidad de que el asistente genere respuestas repetitivas.
- Funcionamiento: Esta penalización se aplica a las respuestas que son similares a las generadas anteriormente.
- Lógica: El modelo calcula una puntuación de repetición para cada respuesta y reduce la probabilidad de seleccionar aquellas con puntuaciones altas.
- Efectos: Una penalización de repetición alta reduce la redundancia y aumenta la variedad de las respuestas, mientras que una penalización baja permite más repeticiones, especialmente en conversaciones largas.
- Ajuste: La penalización de repetición se ajusta manualmente o mediante algoritmos de optimización.
5. Top K:
- Definición: Top K controla la cantidad de respuestas que el modelo considera antes de seleccionar la final.
- Funcionamiento: Similar a Top P, Top K indica la cantidad de respuestas que se evaluarán antes de tomar la decisión.
- Lógica: El modelo calcula la probabilidad de cada respuesta y selecciona la que tenga mayor probabilidad dentro del conjunto Top K.
- Efectos: Un Top K alto aumenta la previsibilidad y confiabilidad de las respuestas, mientras que un Top K bajo permite respuestas más diversas e inesperadas.
- Diferencia con Top P: Top K considera todas las respuestas posibles, mientras que Top P solo considera las más probables.
- Ajuste: Top K se ajusta manualmente o mediante algoritmos de optimización.
En resumen:
- La configuración de los parámetros del asistente de IA permite ajustar su comportamiento y adaptarlo a las necesidades específicas de cada aplicación.
- Es importante comprender la función y el impacto de cada parámetro para lograr un equilibrio entre creatividad, precisión, confiabilidad y diversidad en las respuestas.
- El ajuste fino de estos parámetros requiere experiencia en aprendizaje automático y procesamiento del lenguaje natural.
Ejemplos de código en Python para los parámetros de un asistente de IA
Nota: Estos ejemplos son simplificaciones y no representan la implementación completa de un asistente de IA. Se utilizan para ilustrar los conceptos de forma didáctica.
1. Temperatura:
Python
import numpy as np
def generar_respuesta(modelo, consulta, temperatura):
# Generar predicciones del modelo
predicciones = modelo.predict(consulta)
# Aplicar la función de temperatura
probabilidades = np.exp(predicciones / temperatura)
probabilidades /= np.sum(probabilidades)
# Seleccionar una respuesta aleatoria
respuesta = np.random.choice(modelo.vocabulario, p=probabilidades)
return respuesta
En este ejemplo, la temperatura se utiliza para modificar las probabilidades de las predicciones del modelo. Un valor de temperatura alto aumenta la probabilidad de seleccionar respuestas menos probables, mientras que un valor bajo favorece las respuestas más probables.
2. Top P:
Python
import numpy as np
def generar_respuesta(modelo, consulta, top_p):
# Generar predicciones del modelo
predicciones = modelo.predict(consulta)
# Ordenar las predicciones por probabilidad
predicciones_ordenadas = np.argsort(predicciones)[::-1]
# Seleccionar las top_p respuestas
respuestas_top_p = predicciones_ordenadas[:top_p]
# Seleccionar una respuesta aleatoria del conjunto top_p
respuesta = np.random.choice(respuestas_top_p)
return respuesta
En este caso, Top P limita el conjunto de respuestas a considerar a las top_p más probables. Esto reduce la aleatoriedad y aumenta la previsibilidad de las respuestas.
3. Penalización de repetición:
Python
import numpy as np
def generar_respuesta(modelo, consulta, penalizacion_repeticion):
# Generar predicciones del modelo
predicciones = modelo.predict(consulta)
# Calcular la penalización de repetición
penalizacion = np.zeros_like(predicciones)
for respuesta in respuestas_anteriores:
if respuesta in consulta:
penalizacion[respuesta] += penalizacion_repeticion
# Aplicar la penalización a las probabilidades
probabilidades = np.exp(predicciones - penalizacion)
probabilidades /= np.sum(probabilidades)
# Seleccionar una respuesta aleatoria
respuesta = np.random.choice(modelo.vocabulario, p=probabilidades)
# Actualizar las respuestas anteriores
respuestas_anteriores.append(respuesta)
return respuesta
Aquí, la penalización de repetición reduce la probabilidad de seleccionar respuestas que ya han sido generadas anteriormente. Esto ayuda a evitar la redundancia y a mantener la conversación fluida.
4. Top K:
Python
import numpy as np
def generar_respuesta(modelo, consulta, top_k):
# Generar predicciones del modelo
predicciones = modelo.predict(consulta)
# Ordenar las predicciones por probabilidad
predicciones_ordenadas = np.argsort(predicciones)[::-1]
# Seleccionar las top_k respuestas
respuestas_top_k = predicciones_ordenadas[:top_k]
# Seleccionar una respuesta aleatoria del conjunto top_k
respuesta = np.random.choice(respuestas_top_k)
return respuesta
Top K funciona de manera similar a Top P, pero en lugar de seleccionar las respuestas más probables, selecciona las top_k con mayor probabilidad, independientemente de su valor exacto. Esto puede aumentar la diversidad de las respuestas, incluso si algunas son menos probables.
Explicación del funcionamiento:
- Temperatura: La temperatura actúa como un factor de aleatoriedad. Un valor alto aumenta la exploración del espacio de respuestas, mientras que un valor bajo lo restringe a las opciones más probables.
- Top P: Top P define un umbral de probabilidad. Solo las respuestas que superan este umbral se consideran para la selección final.
- Penalización de repetición: Esta penalización desfavorece las respuestas que ya han sido generadas anteriormente, promoviendo la variedad y evitando la redundancia.
- Top K: Top K selecciona un conjunto fijo de las respuestas con mayor probabilidad, independientemente de su valor exacto. Esto puede incluir respuestas menos probables pero creativas.
Consideraciones importantes:
- La elección de los valores para estos parámetros depende del contexto específico y los objetivos del asistente de IA.
- Es importante